6000台电脑一起找猫 JOHN MARKOFF 报道 2012年07月06日 
Jim Wilson/The New York Times 一幅猫的图像,神经网络能够自行对其进行识别。
加利福尼亚州山景城——“X实验室”是谷歌的秘密实验室,以发明无人驾驶汽车和增强现实眼镜而闻名。几年前,一个研究小组开始在这里研究仿真人脑。
在这里,谷歌的科学家们将16000个计算机处理器联接起来,建造了一个超大规模的机器学习神经网络。他们把这个网络放置在互联网上,任其自主学习。
面对YouTube视频里的大约1000万张数码图片,“谷歌大脑”能做些什么呢?他们要做的是成千上万的人在YouTube上所做的事情:找猫。
这个神经网络自主学习识别猫儿的方法, 说实在的,这可不是什么琐碎无聊的举动。本周,研究人员将在苏格兰爱丁堡的一次会议上展示自己的研究成果。
谷歌科学家和程序设计员将会说明,虽然互联网上充满猫儿视频的事情已经不再是什么新闻,模拟的结果还是让他们大吃了一惊。
这个系统在20000个不同物体里识别目标物的精确度大致上提高了一倍,远远高于以往的任何一次同类实验。
新生代的计算机科学得益于计算成本的降低,以及在巨型数据中心使用大型计算机集群的可能性。这项研究便是其代表,将给机器视觉和知觉、
语音辨识以及语言翻译等诸多领域带来重要进步。
虽然研究人员所使用的某些计算机科学概念以前就存在,此次软件模拟却拥有十分巨大的规模,足以构筑之前不可能实现的学习系统。
利用此类科技的并非只有谷歌的研究人员,他们所做的研究被称为“深度学习”模式。去年,微软科学家所展示的研究成果表明,
该科技也可以被用来建造能理解人类语言的计算机系统。
在纽约大学库兰特数学科学研究所(the CourantInstitute ofMathematical Sciences at New York University)从事机器学习技术研究的计算机科学家严恩·勒坤(YannLeCun)说:
“现在这是语音辨识领域最热门的事。”
当然,还有猫。
为了找到猫,由斯坦福大学(StanfordUniversity)的计算机学家安德鲁·吴(Andrew Y. Ng)和谷歌员工杰夫·迪安(Jeff Dean)
领导的谷歌研究小组用16000个处理器建造了一个神经网络,这个网络有10亿多个连接点。随后,他们向这个系统随机提供从1000万个YouTube视频中截取的缩略图,每个视频截取一张。
目前,多数商业机器视觉技术都是通过标注详细特征,由人工“指导”学习过程来完成的。而在谷歌的此项研究中,机器在识别特征时未得到任何辅助。
吴说:“我们的理念就是,把大量数据交给算法去处理,然后让数据自己说话,让软件自动从这些数据中学习,而不是由大量的研究人员去突破推进。”
“在训练中我们从未告诉过它,‘这就是猫,’”迪安说。最初,他帮谷歌设计了能轻松将程序集分解为多项任务的软件,以便同时处理多个任务。
“基本上是这个系统自主创造了‘猫’这个概念。系统甚至可能会找出猫的侧影图片。”
面对成千上万张图像,“谷歌大脑”使用了一组存储单元,逐步筛选出猫的共同特征,合成了一张朦胧的数码图像。此外,科学家们表示,
他们似乎创建了一个人工智能系统,功能与人脑视觉皮质中发生的活动类似。
神经系统科学家们还探讨过制造所谓“祖母神经元”的可能性。这是人脑中的一些特化细胞,当某人的头像反复出现,
或者“训练”它们识别某个头像时,它们就会产生反应。
“只有通过不断重复,你才能记得朋友的长相,”加利福尼亚州帕洛阿尔托“工业知觉”(IndustrialPerception神经系统科学家加里·布拉德斯基(Gary Bradski)说。
计算机模型特定记忆区域里同时出现的猫图像、人脸和人类身体部分让科学家们十分震惊,但吴表示,他的态度比较谨慎,不会把这个软件系统和生命体划上等号。
吴说:“有人把我们所设置的数值参数比成神经元上的突触,这样的类比是不太严密甚至可怕的。”他表示区别在于,
尽管科学家们所使用的计算机处理能力很强大,但在人脑连接点的数量面前,它还是很微不足道。
研究人员写道:“值得注意的是,和人脑视觉皮质相比,我们的系统仍然渺小。人脑视觉皮质上的神经元和突触的数量比它多出了106倍。”
虽然在生物大脑的庞大规模面前显得渺小,谷歌的研究还是提供了新的证据,证明在给予机器海量数据之后,现有的机器学习算法可以得到极大的提高。
佐治亚理工学院计算机系(Georgia Tech College ofComputing)高性能计算系统实验室执行主任戴维·巴德(David A. Bader)表示:“和原来相比,
斯坦福和谷歌的研究报告把神经网络的规模上限提高了一个量级。”他说,计算机科技的迅速发展会在相对较短的时期内缩小电脑和人脑的差距。“
在这个十年结束之前,整个儿地模拟人类视觉皮质也不是不可能的事情。”
谷歌的科学家表示,现在这一研究项目已经移出谷歌X实验室,由负责搜索业务及相关服务的部门接手。未来可能的应用方向包括改进图像搜索、语音识别和机器语言翻译。
尽管取得了这些成功,谷歌的科学家们仍然出言谨慎,不敢断言自己已经拿到了机器自主学习技术的圣杯。
吴说:“如果我们要做的只是采用现在的算法然后将其扩大,那就太棒了,但是直觉告诉我,我们还没有找到正确的算法。”
翻译:柳沉
喵 ~
|  /1
/1 



 狗仔卡
狗仔卡 发表于 2012-7-23 18:36:46
发表于 2012-7-23 18:36:46
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡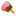 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡 发表于 2012-7-24 08:00:51
发表于 2012-7-24 08:00:51